How to Enable XPath in Internet Explorer
• Erik L. Arneson
Yesterday, I shared a little bit about using a virtual machine to test frontend code under Internet Explorer (IE). My goal was to use Wicked Good XPath to add the proper XPath features to IE so that EPUB.js would work correctly, thus making the Philalethes E-Bulletin Online Reader work on all major browsers.
Well, I’d been thinking about this problem for a while, but had delayed working on it because I just didn’t want to fiddle with IE. While I’d been thinking about it, the EPUB.js instructions were updated with IE-specific steps. I didn’t have to look far.
After loading wgxpath.install.js in the header, I just had to add this bit of JavaScript before anything important happened:
// Internet Explorer workaround.
if (!window.XPathResult) {
EPUBJS.Hooks.register("beforeChapterDisplay").wgxpath = function(callback, renderer){
wgxpath.install(renderer.render.window);
if (callback) callback();
};
wgxpath.install(window);
}
You can see on line 2 that I test for window.XPathResult instead of looking for a user agent or anything like that. That’s because it’s not really IE I’m interested in detecting. I want to find out if XPath is both available and somewhat standard. User agents are unreliable. Always test for feature availability instead!
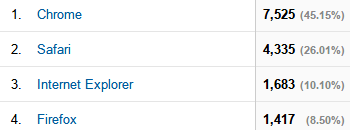 The results are good enough for now: the Online Reader works in IE, but it’s not perfect. The cover image doesn’t load full-size and fonts don’t seem to be loading correctly. IE users account for only 10% of the traffic on the website, so obviously I need to work on the EPUB.js cross-browser support. For now, though, it works. And it looks great on Chrome, Safari, and Firefox.
The results are good enough for now: the Online Reader works in IE, but it’s not perfect. The cover image doesn’t load full-size and fonts don’t seem to be loading correctly. IE users account for only 10% of the traffic on the website, so obviously I need to work on the EPUB.js cross-browser support. For now, though, it works. And it looks great on Chrome, Safari, and Firefox.